
Machine Learning and AI: From Basics to Mastery
Create your First ML Application using Streamlit


You have worked on a spectrum of Machine Learning problems, worked on various data science courses, spent hours on data science projects, and also dealt with various datasets available. For any project you mention in your resume, it’s always a cherry on the cake to present your projects in a form of a Web Application. This not only shows your Machine learning skills but also shows the recruiter that you can embed your ML projects as a web application. By the end of this blog, you are going to get comfortable with using Streamlit to build a basic Streamlit web application that you can easily customize for any of your Machine learning Projects.
Streamlit is an open-source app framework that is the easiest way for data scientists and machine learning engineers to create beautiful, performant apps in only a few hours! Under the hood, it uses React as a frontend framework to render the data on the screen. So, React Developers can easily manipulate the UI with few changes in the code.

The dataset we would be dealing with demonstrates building our basic web application on Streamlit. It is a simple Iris dataset extracted from Kaggle. It includes three iris species with 50 samples each as well as some properties of each flower. One flower species is linearly separable from the other two, but the other two are not linearly separable from each other. The link for this dataset can be found here.
In this web application, we will enable users to select the dimensions of petal and sepal lengths of the iris flower, and based on the dimensions selected by our users, our application will be predicting which iris species the dimensions belong to!
We will be training this dataset, using a simple logistic regression technique (not giving much emphasis on the training part), and saving the trained model as a Pickle file.
Python pickle module is used for serializing and de-serializing a Python object structure. Any object in Python can be pickled so that it can be saved on disk, in our case we will be saving our trained model in a pickle file and later will be using that model for predictions in the back-end of our application. Please refer to this GitHub link for directly downloading the pickle file for iris data.
Before starting off with building the Streamlit application, make sure you have installed streamlit. If not, enter the following command in your respective terminal.

Now, let’s get started!
We’ll start by calling the important libraries, which would be used to build your first Streamlit application, as well as importing our Iris classification model, saved previously as (.pkl) file in a variable named “model”, using pickle.

Importing PIL Library is optional since it's used to import images in our web application, but it is recommended to import because it makes our application more presentable.
Now, we’ll give a header for our application, and import an image, making our application look better.

It’s time to take feature values as input from our users, and based on those inputs, our Iris Classification model would predict the class of the Iris flower respectively. Streamlit provides us wonderful options to accept the inputs in form of text boxes, as well as slider options. Here, we would go with slider options, which makes it easier for users to insert values.
We’ll accept each feature values such as sepal length and width, and petal length and width respectively, using the slider option defining the range between which the user can select a value, and store these values, in a variable named “data”, shown as:

The data, we collected, needs to be converted into a Data Frame, before using this for prediction, which can be done as follows:
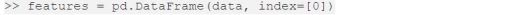
Now, it's time to provide these inputs to our classifier model, which will finally predict the class of the Iris flower, as an Output!

Here, the “predict_proba” command will basically give the prediction, in the form of probability percentages of each class predicted by our model, or you can just use “predict”, to simply predict the class.
We are done with model predictions, except for presenting the results to our users, which can be done by:

Finally, we are done with coding your basic Streamlit web application.
Now perform the following steps, to open your web application, which would render on your local server,
- Open your terminal, and activate the virtual environment (if any).
- Change the directory, in which you have saved the python file of your web application.
- Execute the command, “streamlit run app.py” to render your application on your local server!

Congratulations! You have created your own Streamlit application! Your application would look something like this:
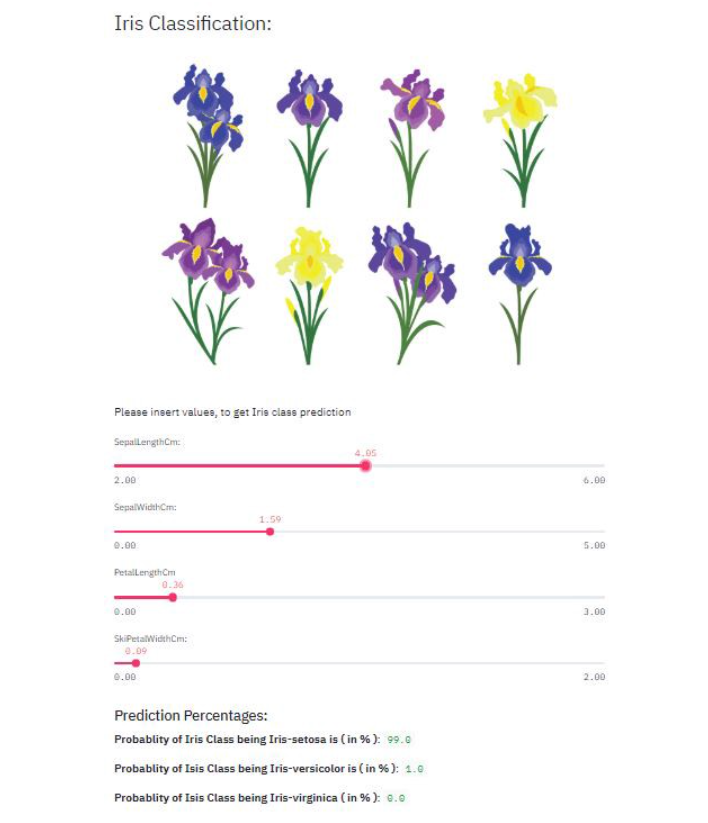
Now, this application can be a baseline step for creating any of such applications of your choice! You can enhance the designing experience by exploring more amazing features offered by Streamlit. Presenting your Machine Learning projects in the form of a web application not only lets you learn data science with an end-to-end approach, but also you get a glance of the data lifecycle which is followed in industries.
Additionally, we would suggest reading the official documentation of Streamlit, which will surely open a spectrum of features you can try with.
Here is the Github Link for the whole Streamlit code.
If you are interested in learning more about Machine Learning, check out Board Infinity's AI and Machine Learning Course with certification! Gain expertise from scratch with the help of top industry experts and land your dream job!