
Introduction
The software can recognize speech in audio and convert it to text using speech recognition. There are numerous interesting use cases for speech recognition, and it is simpler than you might think to incorporate it into your own applications.
Speech recognition is an important feature in many applications, including home automation, artificial intelligence, and so on. This is useful because it can be used with an external microphone on microcontrollers such as Raspberry Pi.
Installations Required
Speech Recognition Module in Python
If the versions in the repositories are too old, run the following command to install pyaudio.
For Python3, use pip3 instead of pip. Installing pyaudio on Windows is as simple as typing the following command into a terminal.
Speech Input via Microphone and Text-to-Speech Translation
Configure Microphone (For External Microphones):
- To avoid glitches, it is best to specify the microphone during the programme.
- For Linux, type lsusb in the terminal, and for PowerShell, Get-PnpDevice -PresentOnly | Where-Object { $_.InstanceId -match ‘^USB’ } command to list the connected USB devices.
- A list of connected devices will be displayed. The microphone's name would be something like this.
Set Chunk Size:
- This simply means deciding how many bytes of data to read at once. This value is typically specified in powers of two, such as 1024 or 2048.
Set the sampling rate:
- The sampling rate determines how frequently values are recorded for processing.
Set the Device ID to the selected microphone:
- In this step, we specify the device ID of the microphone we want to use to avoid ambiguity in the event that there are multiple microphones. This also aids debugging because we will know whether the specified microphone is recognized while running the program. We specify a parameter device id during the program. If the microphone is not recognized, the program will report that the device id could not be found.
Allow Adjusting for Ambient Noise:
- Because ambient noise varies, we must give the program a second or two to adjust the recording's energy threshold so that it is adjusted according to the outer level of noise.
This is accomplished with the assistance of Google Speech Recognition.
- To function, you must have an active internet connection. However, some offline recognition systems, such as PocketSphinx, have a lengthy installation process that necessitates the installation of several dependencies. Google Speech Recognition is among the most user-friendly.
Diagnosing
The following issues are frequently encountered:
Muted Microphone: This results in no input being received. Alsamixer can be used to test for this. It is possible to install it using
Enter amixer, The result will look something like this:
The capture device is currently turned off, as you can see. Type alsamixer to enable it. It is displaying our playback devices, as seen in the first image. Toggle to Capture devices by pressing F4.
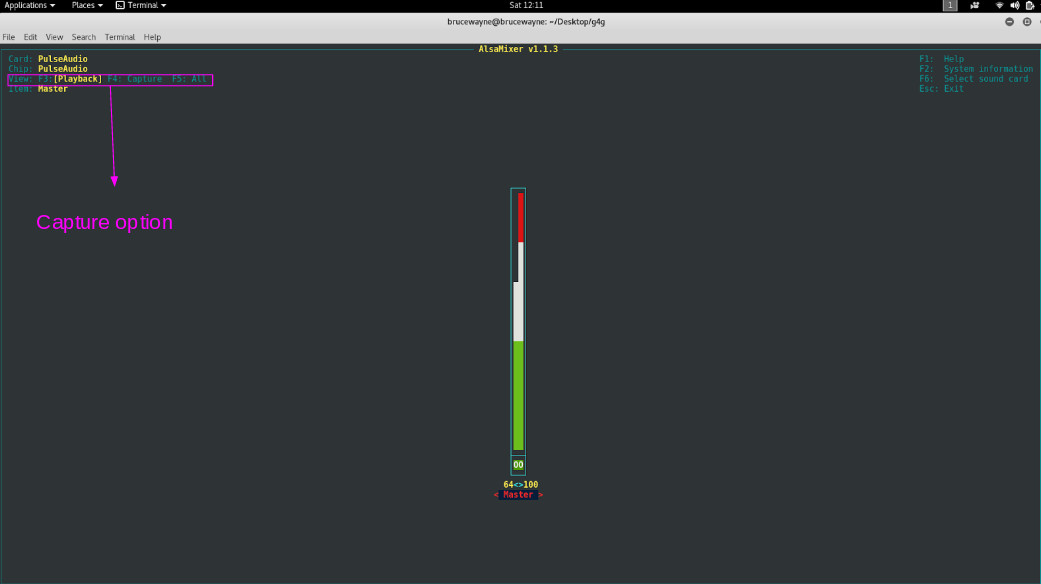
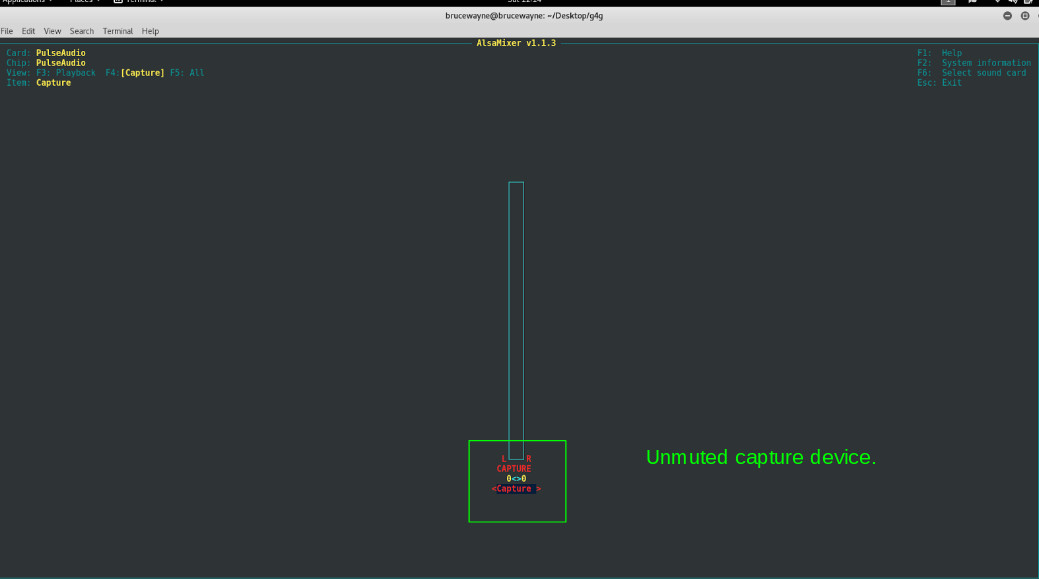
The highlighted area in the second image indicates that the capture device is muted. Press the space bar to unmute it.

The highlighted part in the last image confirms that the capture device is not muted.
The current microphone has not been chosen as a capture device: In this case, type alsamixer and select sound cards to configure the microphone. You can choose the default microphone device here. The highlighted area in the image is where you must select the sound card.

The second image depicts the sound card screen selection.
This is how you can play with your laptop by using simple python commands.