
NLP Fundamentals: From Basics to Mastery
The trendiest topic in ML - Natural Language Processing


Machine learning is the study of a rich set of sophisticated algorithms (combining concepts of statistics & software engineering) which is aimed at providing automated instructions to systems & machines so that they could self-act rather than depend on human inputs for deciding their next course of action.
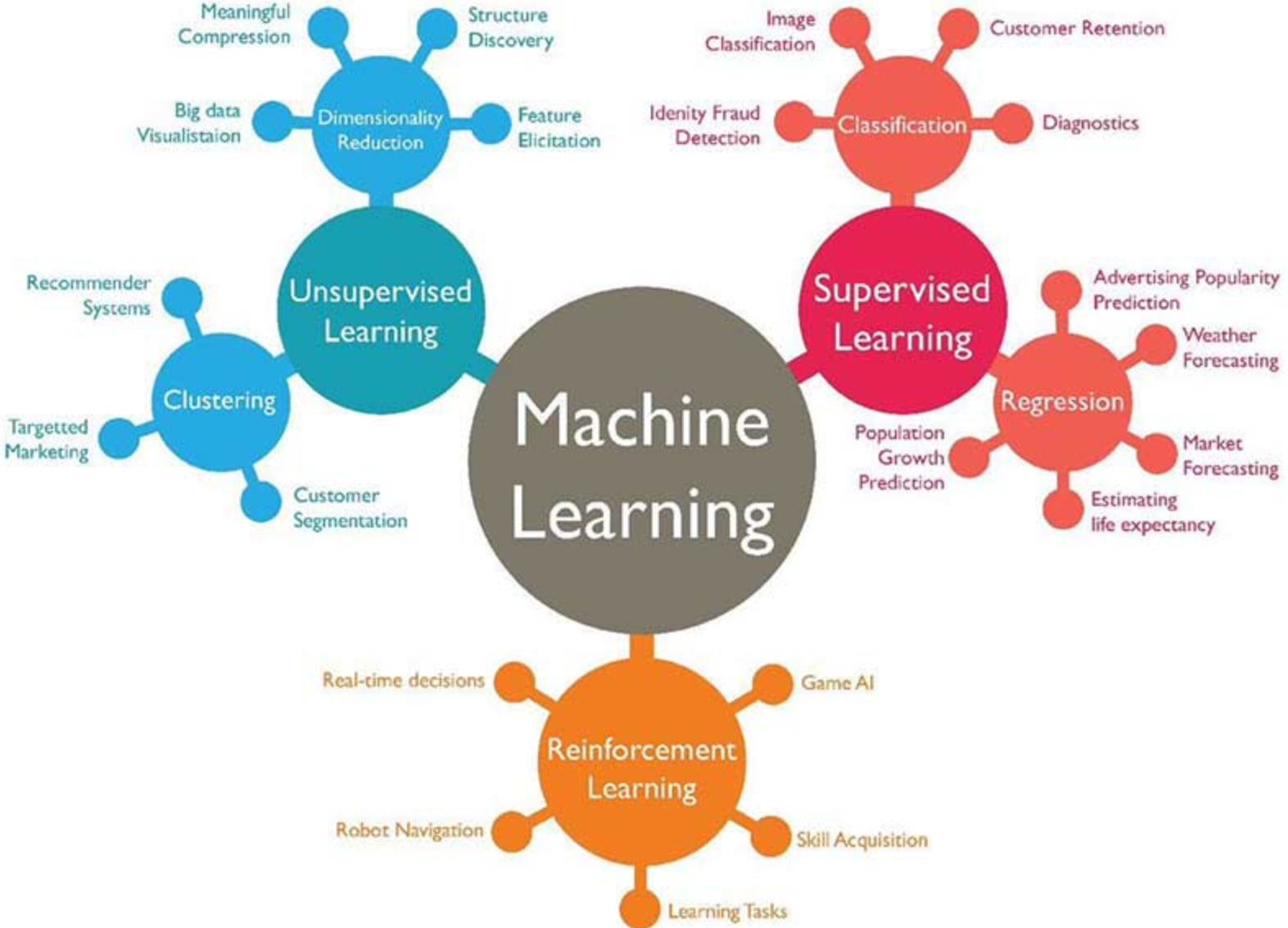
There are many components of machine learning; which are bucketed into three major components – supervised learning, unsupervised learning, and reinforcement learning. The categorization is primarily done on the strategy & nature of the dataset used to train the existing data to make real-time decisions.
Now, not all data are in a text or numeric format; there are multiple forms of data such as images, sound etc. which needs to be massaged as well as useful information can be extracted from the same. There comes the concept of Natural Language Processing.
1. What is Natural Language Processing; what does it encompass?
Natural Language Processing is one of the most trending & sophisticated forms of human-machine interaction which focuses on linguistics; and enables machines & systems to both read and interpret natural language.
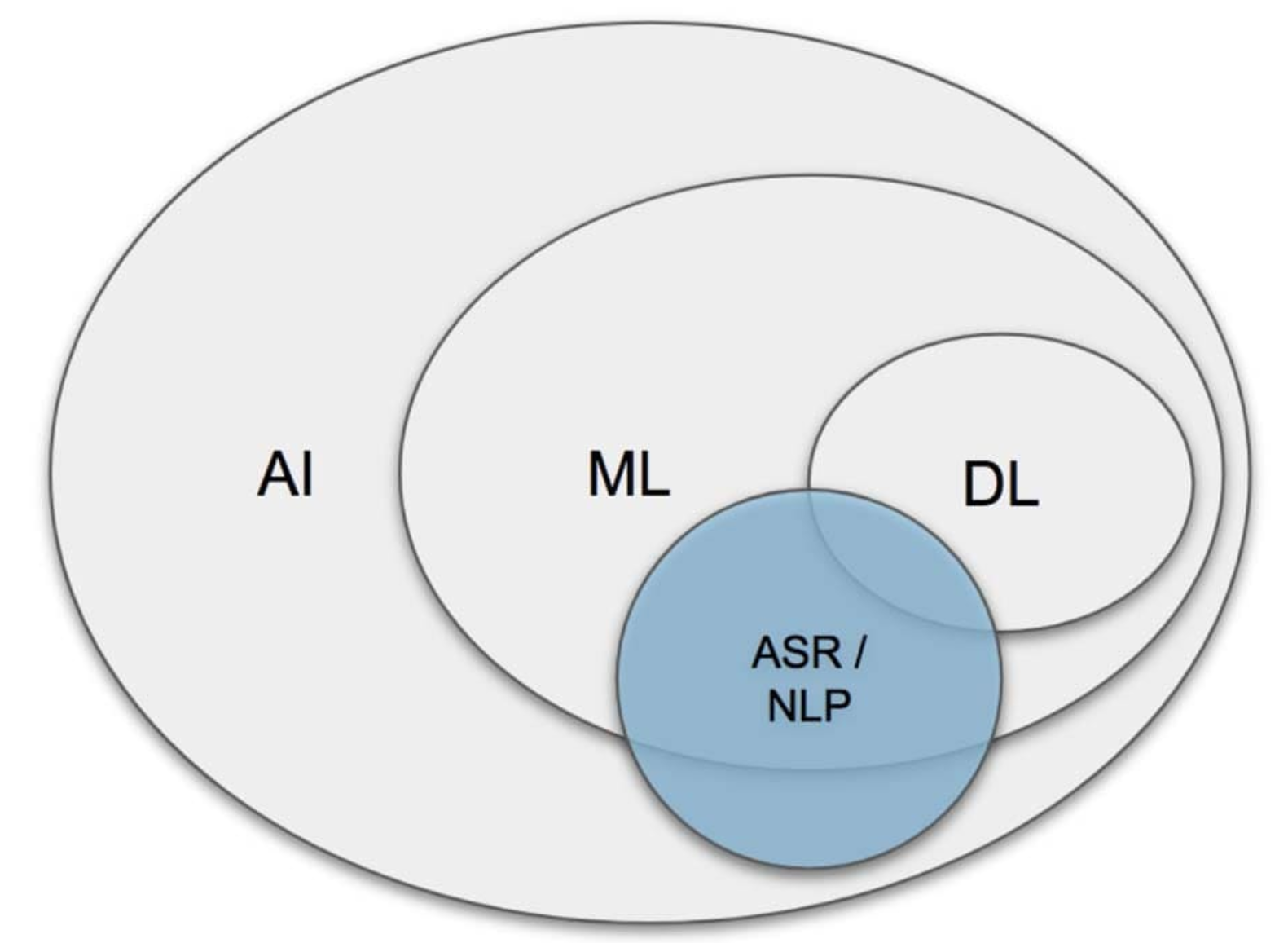
As evident from the figure, NLP is not a complete subset of Machine language; rather there’s a substantial correlation between ‘Natural language Processing’ and ‘Machine Language’ specifically in training machines & systems which deal with speech data. Also, NLP works in close synchronization with ASR as well; wherein ASR is responsible for converting human speech to text, and NLP is responsible in processing the text generated from ASR; so as to generate insights and knowledge from the extracted text.
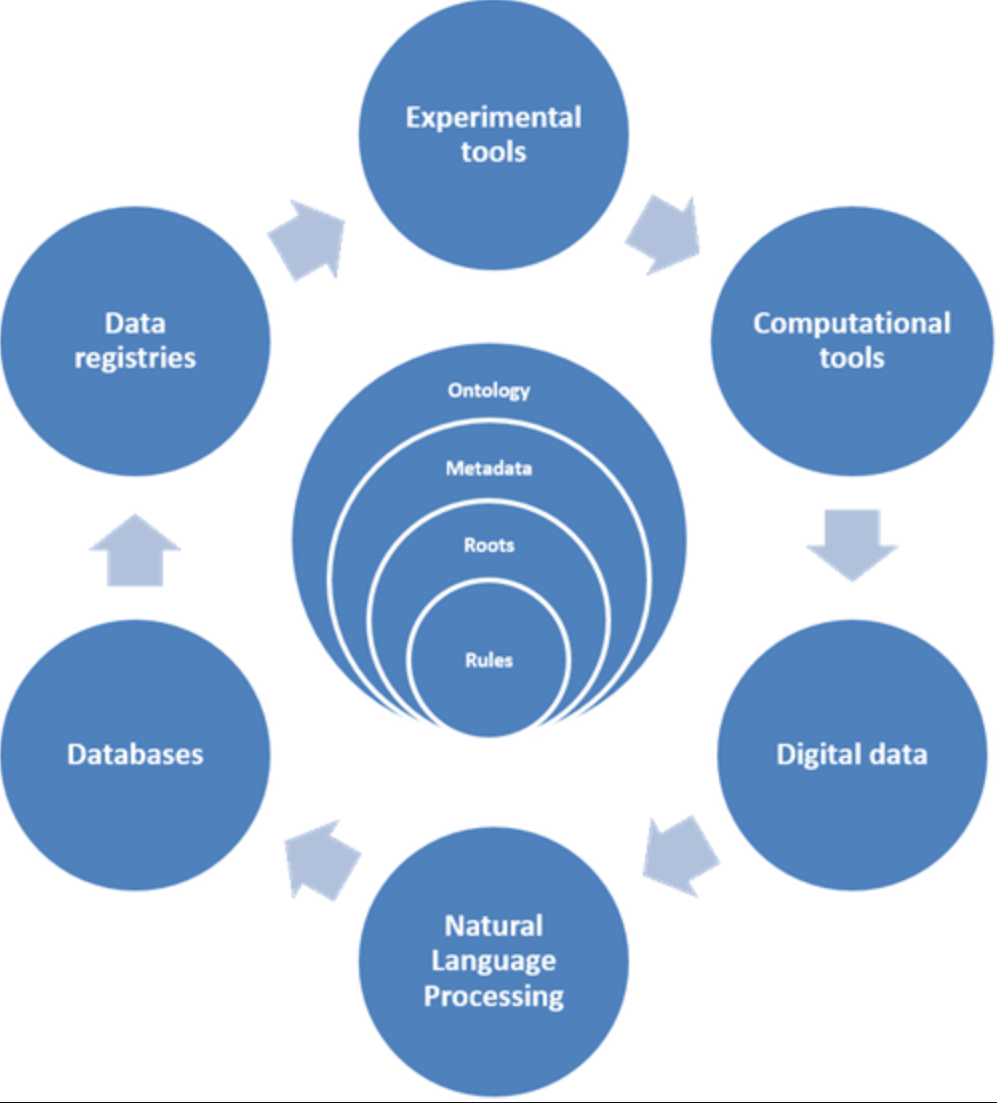
Now, coming to the second part i.e. what does NLP encompasses – there are a variety of factors and dependencies which need to be taken care of in order to implement a wholesome NLP engine. A few of the components include digital data, data storage & processing, registry, computational tools, protocols that needs to be followed in converting speech to text, metadata, and so on. Other than that, as shown in the figure as well; the NLP engine is cyclic in nature incorporating a closed feedback system i.e. the output of the first iteration gets back as the input to the next – this is how the systems learn from historical data trends & patterns; and improves its throughput and accuracy with each iteration.
2. What are the different steps to implementing an NLP engine?
Before coming to the stepwise execution of a typical NLP project; it must be noted that NLP per se deals with extracting insights or intelligence from the text. The stepwise process used to implement an NLP engine is mentioned below for reference –
Step 1 – Segmentation of the text; this process advocates the ‘divide and rule principle’ and segments a paragraph text into logical sentences revealing certain sentiments or meanings
Step 2 – Tokenization of words; this is a further drill down to the first step wherein the extracted sentences are further segregated into segment or tonic words communicating any strong sentiment
Step 3 – Identification of part of speech; this is an important step as the part of speech would indicate the message that the particular word is containing. A typical example of the same is shown below –

Step 4 – Lemmatization of text; this deals with converting each of the words in the sentence into the most basic form of speech
Step 5 – Identification of stop words; this forms the base of the statistical analysis. This is the step wherein the keywords are generated that suggests positive or negative sentiments
Step 6 – Dependency parsing; refers to the correlation of each of the stop words with each other; in the context of the sentence or paragraph being analyzedStep 7 – Identification of nouns or other named entities in the sentence; this is simply to ensure that the information-carrying words get the proper priority & prominence